Make sure you have checked the add to path tick boxes while installing python, anaconda.
Refer to this link, if you are just starting and want to know how to install anaconda.
If you already have anaconda and want to check on how to create anaconda environment, refer to this article set up jupyter notebook. You can skip the article if you have knowledge of installing anaconda, setting up environment and installing requirements.txt
- Install necessary libraries from requirements.txt file provided.

- Go to the directory where your requirement.txt file is present.
cd <<directory of your file>>. E.g, If my file is in d drive, then
- cd d:
- cd d:\License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
If your project is in c drive, you can ignore step 1 and go with step 2.
Eg. cd C:\Users\Hi\License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
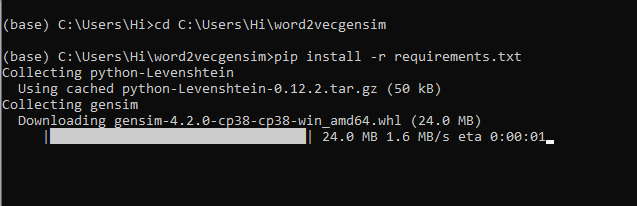
- Run command pip install -r requirements.txtor conda install requirements.txt (Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
All the necessary files will get downloaded. To run the code, open anaconda prompt. Go to virtual environment if created or operate from the base itself and start jupyter notebook, open folder where your code is present.
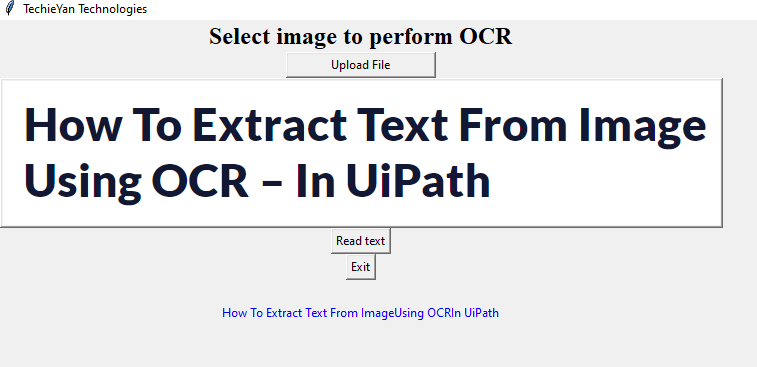
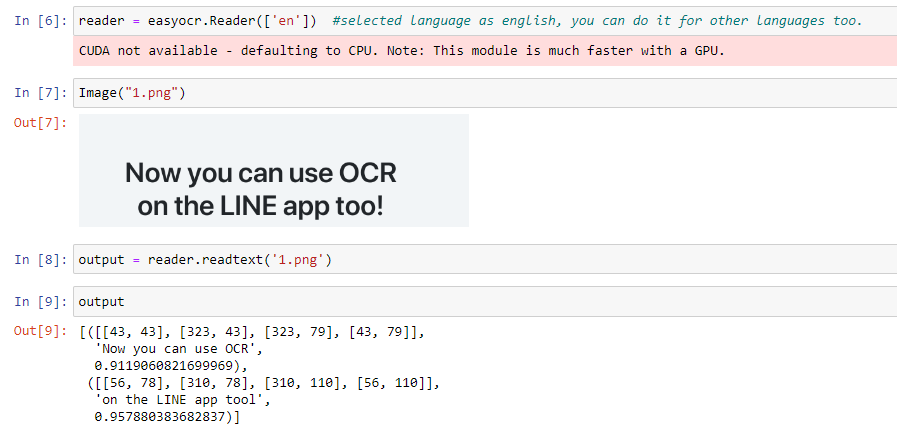
Open “easyocr.ipynb” to get the results.
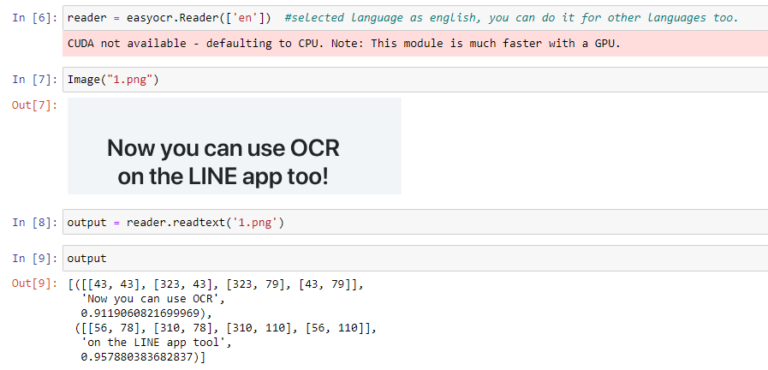
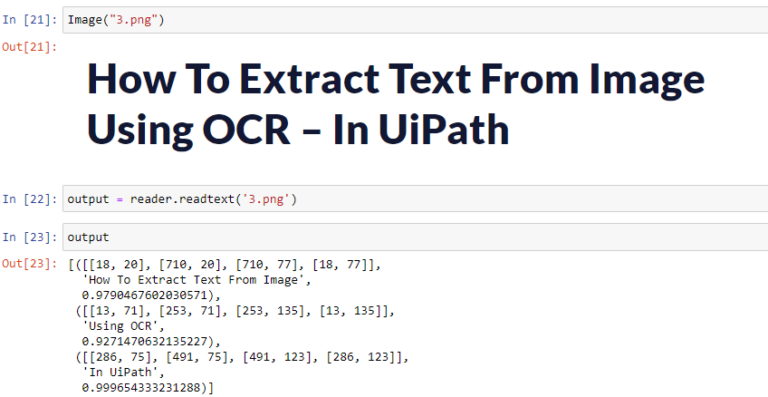
No dataset used. For testing the accuracy of our OCR reader, I have given some images.