
Overview
Sentiment Analysis of Twitter Airlines Data
Phone-alt Youtube Facebook Instagram LinkedinAbstract
Sentiment analysis is a method for generating an emotion given the features for a specific case, such as estimating the emotion/sentiment of a person based on reviews and comments which he had made for a product/customer service. Then using this information, the analysts might get to know the impact of the customer service and the product on the user. Using the results, we can avoid some problems/issues which the user might be facing.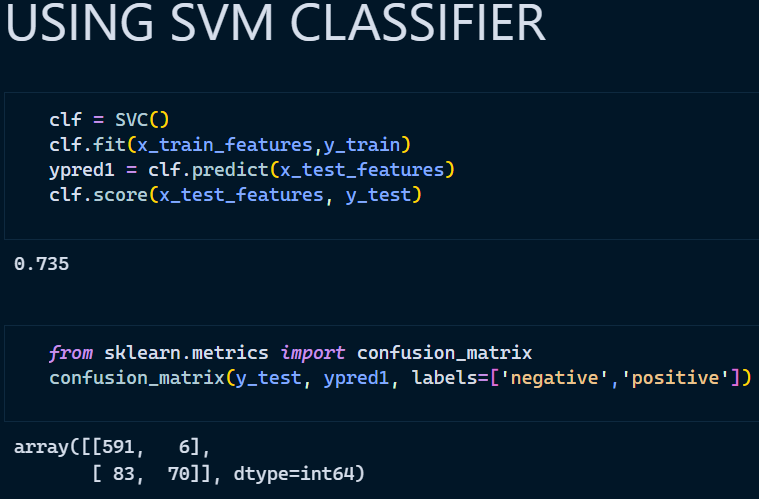
Algorithm Description
Random Forest Classifier:
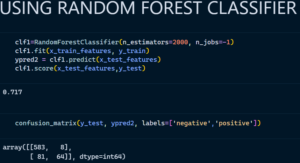
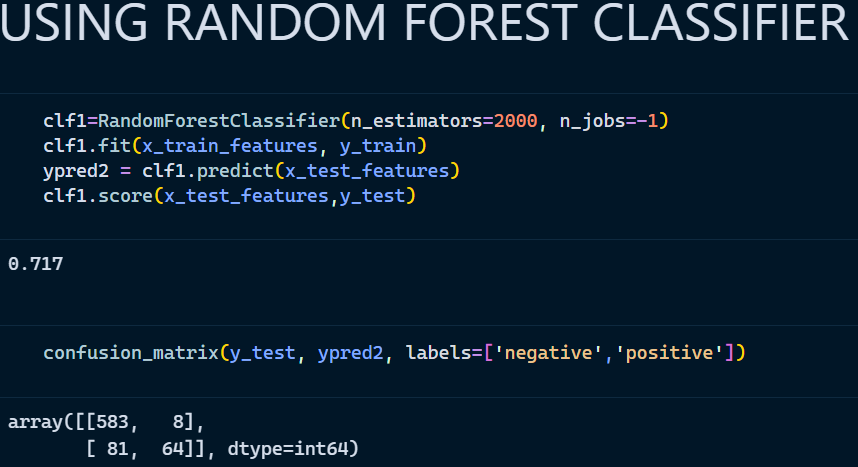
Random Forest Classifier is an ensemble algorithm which works with multiple algorithms parallelly. This is a supervised algorithm and it can be used with both classification and regression problems. The output of the new data is estimated either by using majority voting or average voting technique. Since the algorithm works with bagging technique, multiple decision trees are used to provide the output for the specific input. This is a key difference between decision trees and random forests. While decision trees consider all the possible feature splits, random forests only select a subset of those features. Random forest works best with large datasets and high dimensional.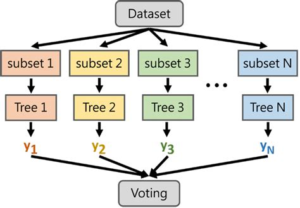 References:
References:
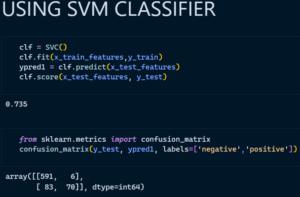
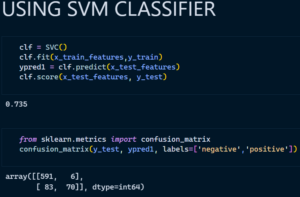
Support Vector Machine:
Support vector machines are basically a supervised learning algorithm which classifies the data points by drawing a linear curve and a non-linear curve depending on the data it is dealing with. The boundary that separated the 2 or more classes is called as a hyperplane, though there is a possibility of having some million hyperplanes for our data, but we need to find the hyperplane with maximum margin from all the training points, which makes the algorithm more efficient while predicting on new dataset, it can easily classify on which side the new data belongs to.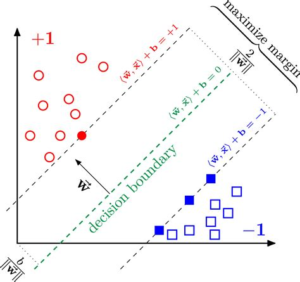
- References:
 References:
References:
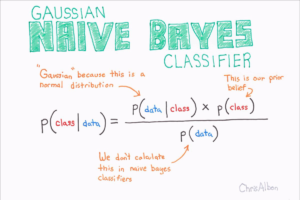
- https://www.geeksforgeeks.org/applying-multinomial-naive-bayes-to-nlp-problems/
- https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html
- https://www.researchgate.net/publication/315869006_Machine_Learning_in_Transportation_Data_Analytics
- https://www.sciencedirect.com/science/article/pii/S235214651830262X
- https://www.researchgate.net/publication/338336513_Transportation_network_model_and_Network_analysis_of_road_networks
How to Execute?
Make sure you have checked the add to path tick boxes while installing python, anaconda. Refer to this link, if you are just starting and want to know how to install anaconda. If you already have anaconda and want to check on how to create anaconda environment, refer to this article set up jupyter notebook. You can skip the article if you have knowledge of installing anaconda, setting up environment and installing requirements.txt- Install the prerequisites/software’s required to execute the code from reading the above blog which is provided in the link above.
- Press windows key and type in anaconda prompt a terminal opens up.
- Before executing the code, we need to create a specific environment which allows us to install the required libraries necessary for sentiment analysis project.
- Type conda create -name “env_name”, e.g.: conda create -name project_1
- Type conda activate “env_name, e.g.: conda activate project_1
- Go to the directory where your requirement.txt file is present.
- cd <>. E.g., If my file is in d drive, then
- d:
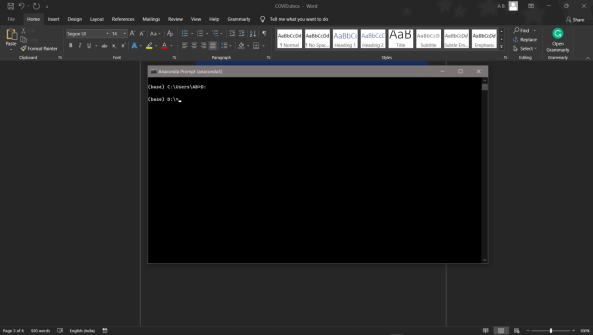 7.cd d:License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
7.cd d:License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
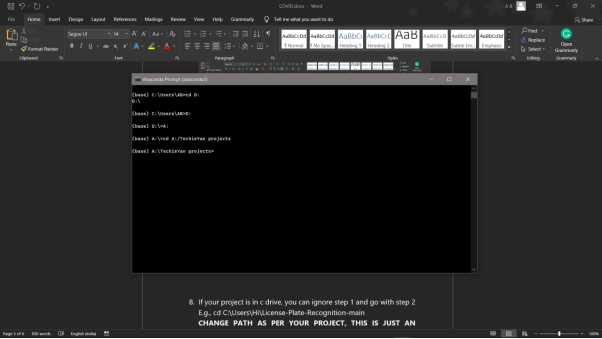 8. If your project is in c drive, you can ignore step 5 and go with step 6
9. g., cd C:UsersHiLicense-Plate-Recognition-main
10. CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
11. Run pip install -r requirements.txt or conda install requirements.txt (Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
8. If your project is in c drive, you can ignore step 5 and go with step 6
9. g., cd C:UsersHiLicense-Plate-Recognition-main
10. CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
11. Run pip install -r requirements.txt or conda install requirements.txt (Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
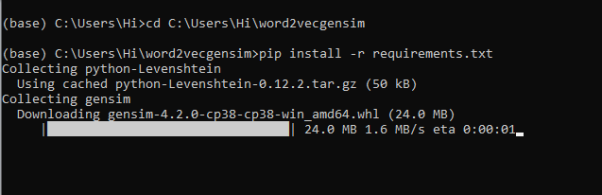 12. To run .py file make sure you are in the anaconda terminal with the anaconda path being set as your executable file/folder is being saved. Then type python main.pyin the terminal, before running open the main.py and make sure to change the path of the dataset.
13. If you would like to run .ipynb file, Please follow the link to setup and open jupyter notebook, You will be redirected to the local server there you can select which ever .ipynb file you’d like to run and click on it and execute each cell one by one by pressing shift+enter.
Please follow the above links on how to install and set up anaconda environment to execute files.
Note: There are 4 different files each seeves different purpose such as,
12. To run .py file make sure you are in the anaconda terminal with the anaconda path being set as your executable file/folder is being saved. Then type python main.pyin the terminal, before running open the main.py and make sure to change the path of the dataset.
13. If you would like to run .ipynb file, Please follow the link to setup and open jupyter notebook, You will be redirected to the local server there you can select which ever .ipynb file you’d like to run and click on it and execute each cell one by one by pressing shift+enter.
Please follow the above links on how to install and set up anaconda environment to execute files.
Note: There are 4 different files each seeves different purpose such as,
- Preprocess.ipynb consists of all the data cleaning steps, which are necessary to build a clean and efficient model.
- main.ipynb consist of major steps and exploratory data analysis which allow us to understand more about the data and behavior of it.
- Variable_Selction.ipynb consists of data reduction/dimensionality reduction techniques such as Sequential feature selector method to reduce the dimensions in the data and compare the model scores before and after dimensionality reduction.
- Combined_main_var.ipynb consists of combination of main.ipynb and variable_selection.ipynb to make it more clear and understable for the audience.
Data Description
The dataset was downloaded from a Kaggle data repository. The dataset has been pre-processed and cleaned to remove any bias while training. Dataset consists of more than 14641 data entries and around 15 columns. Since the data we are dealing with consist of textual data, there should be a lot of pre-processing should be done in order to pass it to the model which we want to train. So, using natural language processing libraries we need to clean our data in the areas such as removing stop words, punctuation’s, normalising the data. Some of the important features which contribute more to the model which we are trying to build are, airine_sentiment, text, tweet_location, negative_reason. Here the target_column is represented by airline_setiment(positive, neutral, negative).
Final Results
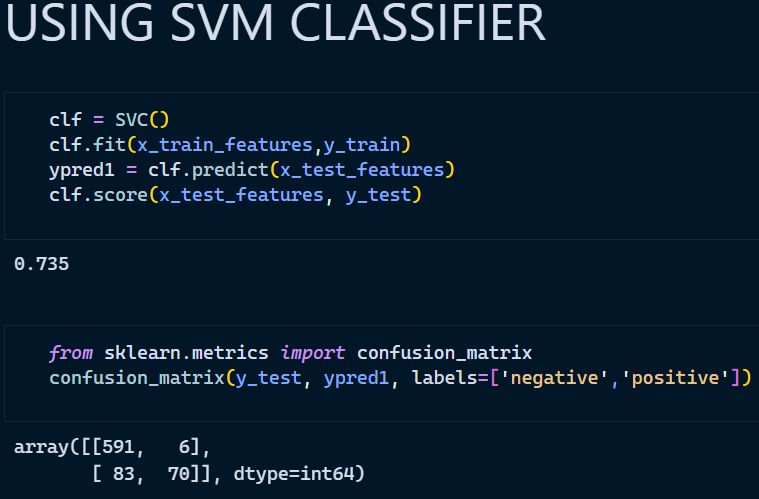
- Support Vector Classifier
 2. Random Forest Classifier
2. Random Forest Classifier
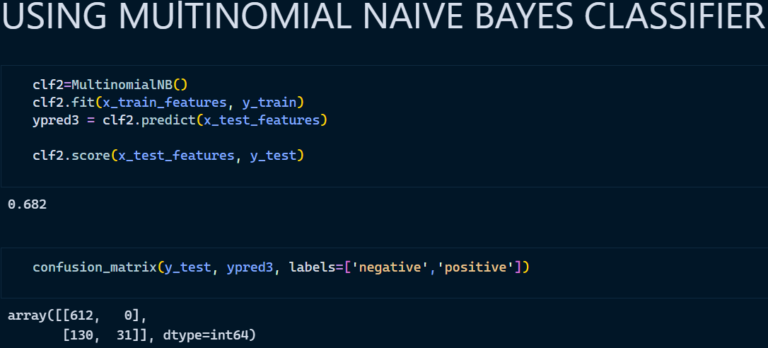
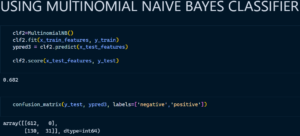
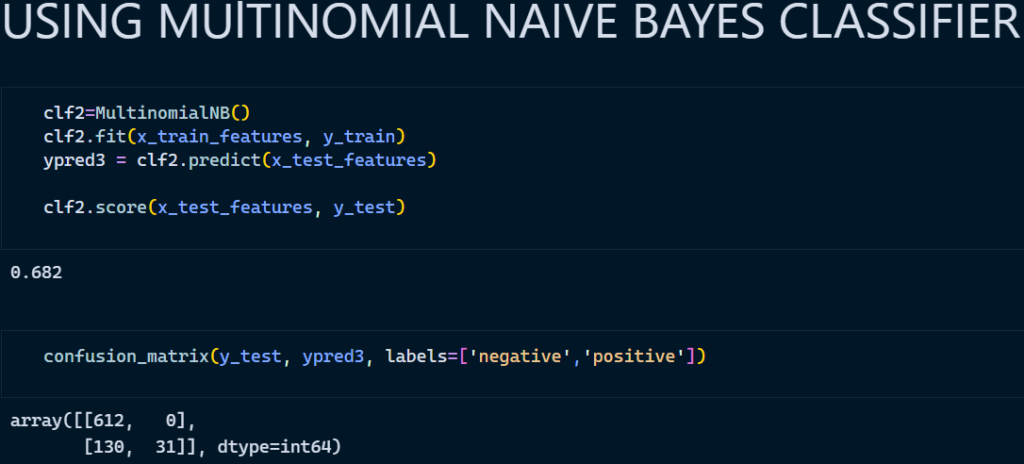
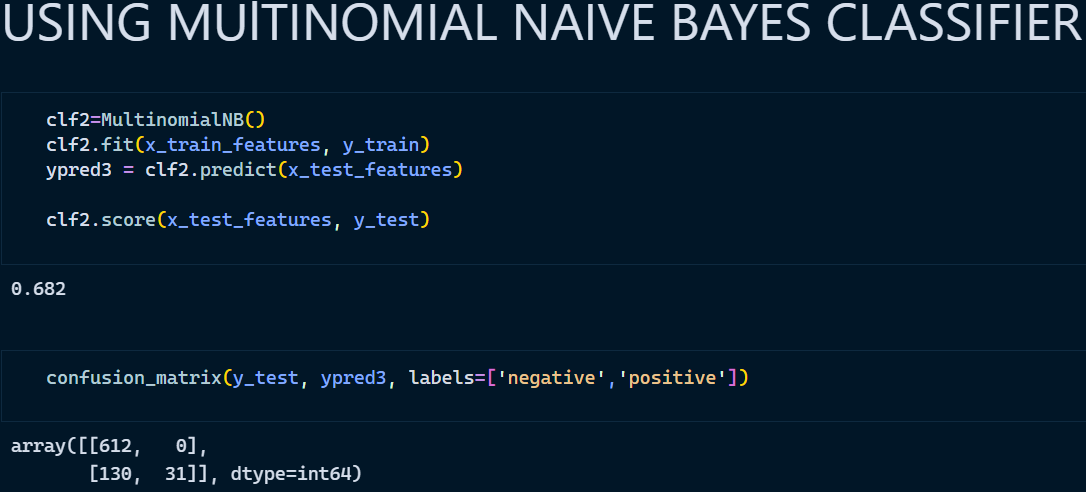
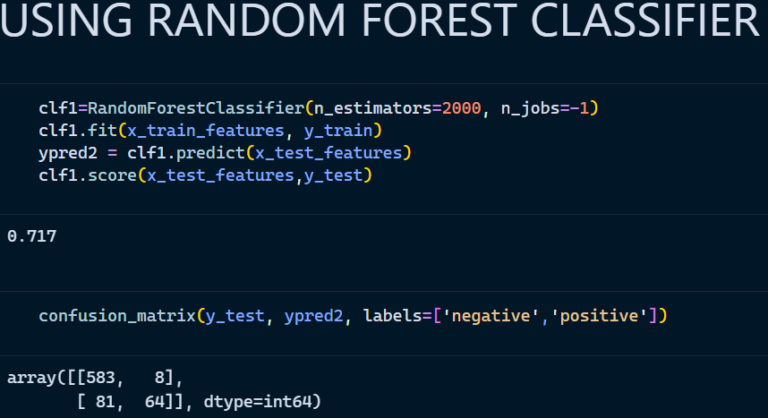 3. Multinomial Naïve Bayes Classifier
3. Multinomial Naïve Bayes Classifier
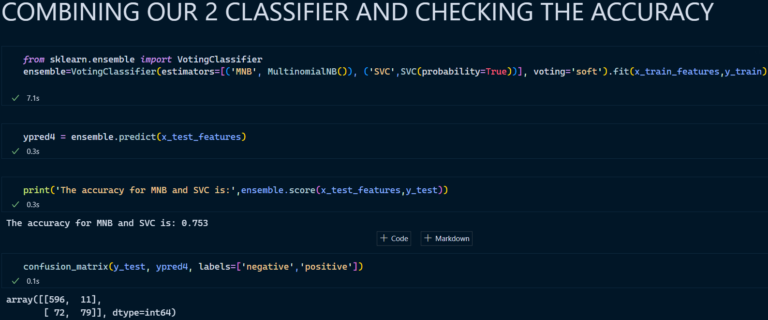
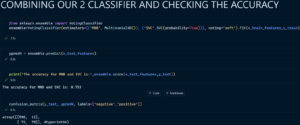
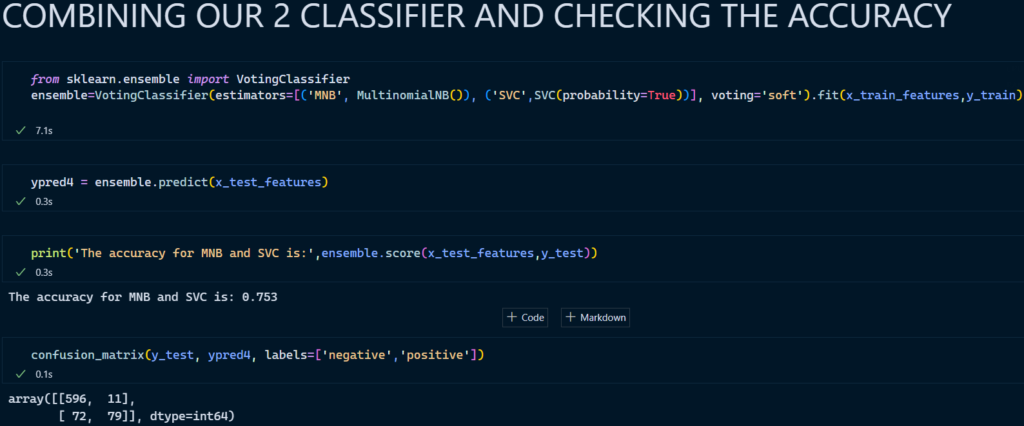
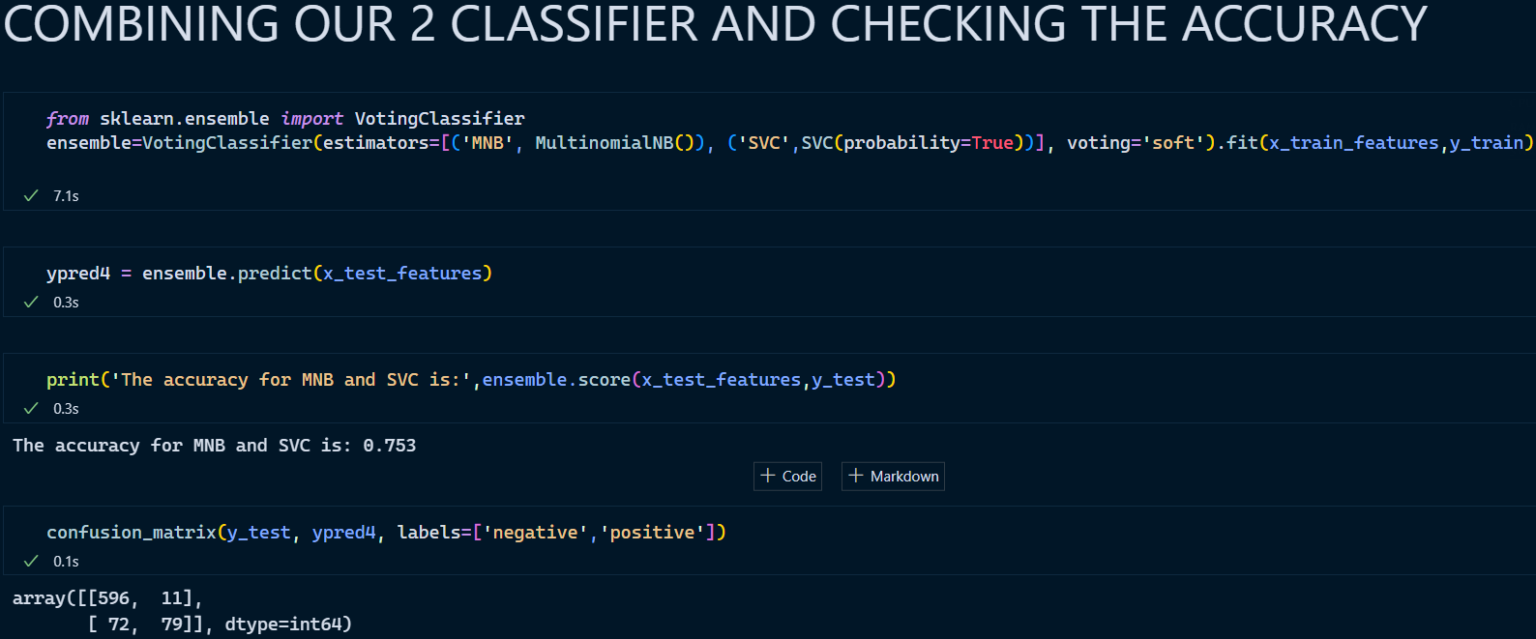
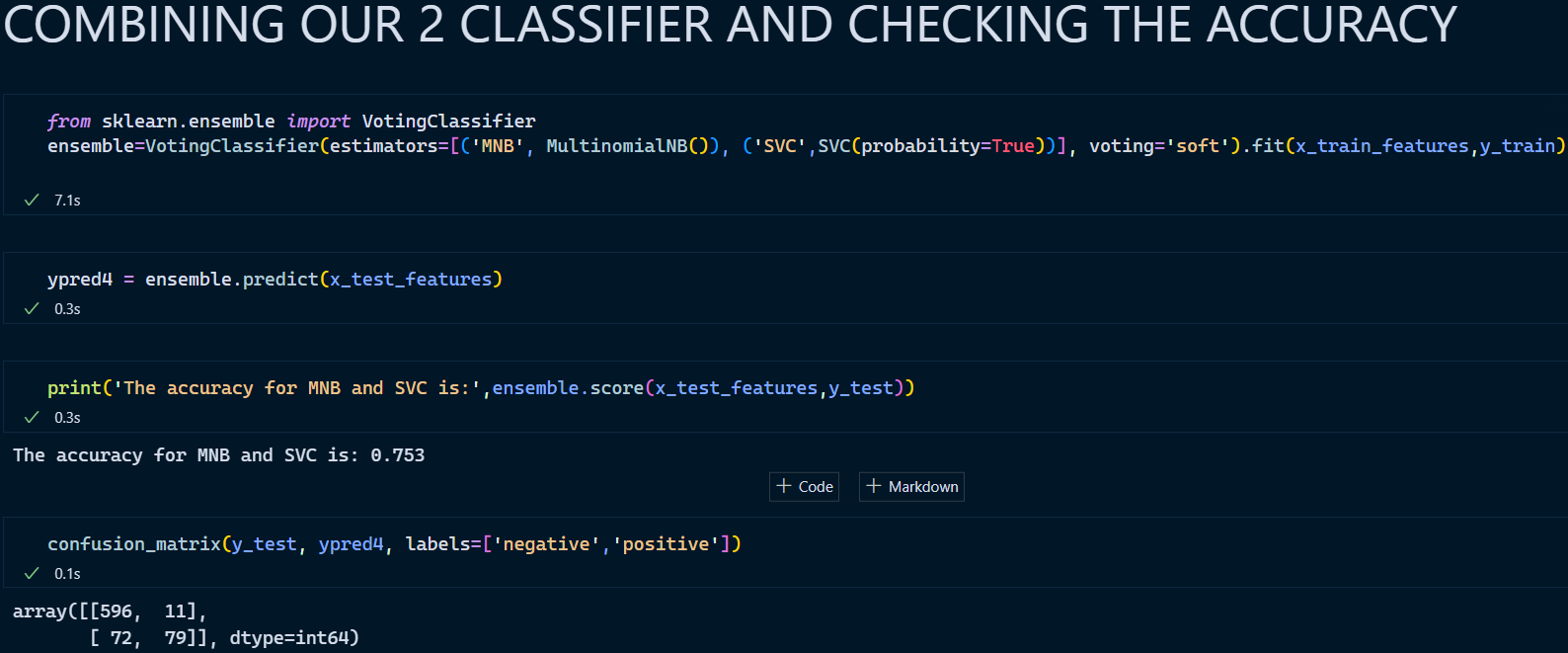
 4. Voting Classifier (Merging 2 Classifiers)
4. Voting Classifier (Merging 2 Classifiers)
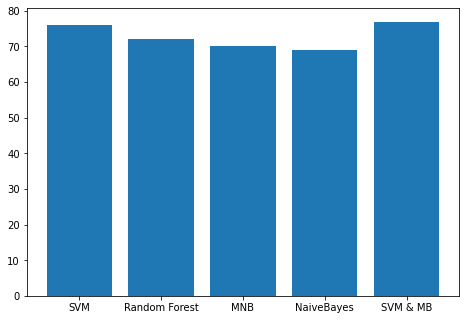
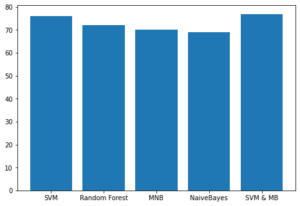
 5. Comparison of 5 Algorithms
5. Comparison of 5 Algorithms
Issues you may face while executing the code
- We might face an issue while installing specific libraries, in this case, you might need to install the libraires manually. Example: pip install “module_name/library” i.e., pip install pandas
- Make sure you have the latest or specific version of python, since sometimes it might cause version mismatch.
- Adding path to environment variables in order to run python files and anaconda environment in code editor, specifically in any code editor.
- Make sure to change the paths in the code accordingly where your dataset/model is saved.


Need the source code or help?
Contact us for model weights, datasets, or guidance on running this project.