
Overview
Movie Recommender System Application
Phone-alt Youtube Facebook Instagram LinkedinAbstract
Recommendation engine is a very popular area of interest on how does the content which we love is delivered to us, so this project explains about the tools and techniques used by the industries which helps them top recommend the stuff which we love to increase their viewership. The main objective of the project is to recommend the movies for the user, the tools which we have used in here are Sklearn, NLTK (natural language tool kit) and pandas’ functionality to manipulate and extract information from the dataset, finally we have used stream lit as a web framework to integrate the code with a small stream lit application, which allows you to get your hands on an actual website where you get the recommendation for your desired movies.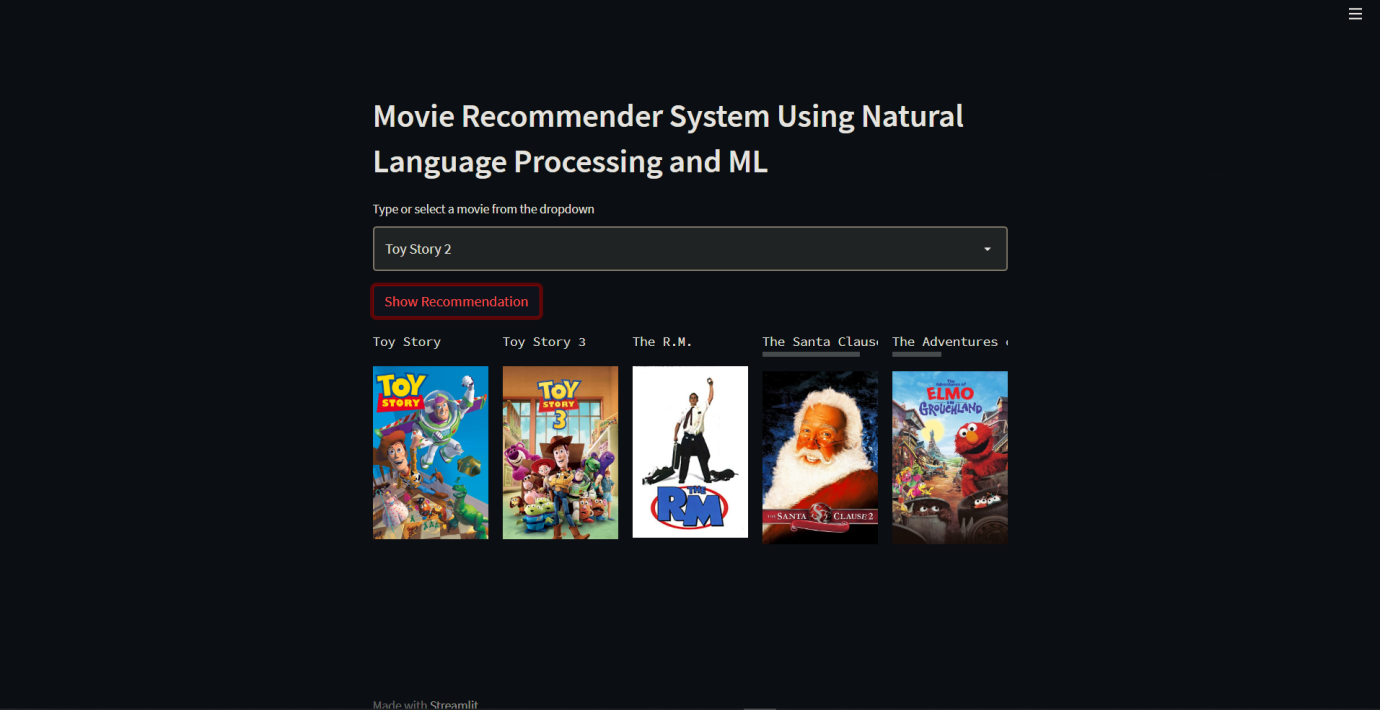
Algorithm Description
Count Vectorizer: They are used for converting a collection of term document to a vector. It also helps the pre-processing of text data prior to generate the representation of vector. They are transformed according to the frequency which comes in the entire text. They create a matrix in which columns are represented as words and rows are represented as text sample. References: Stream lit: Stream lit is a small and easy web framework which helps us to build beautiful websites. The main reason for using stream lit is that it offers very user-friendly experience and we don’t need to have a prior knowledge of HTML, CSS and JAVASCRIPT. Streamlit is mostly used for deploying machine learning models without using any external cloud integrations. Some of the applications of Streamlit are it helps to deploy Machine learning and deep learning models, it can also help us to build a front end for a normal code. The output can be viewed as local server in your web browser. References: DOWNLOAD BASE PAPER- https://www.researchgate.net/publication/283042228_A_Movie_Recommender_System_MOVREC
- https://www.ijcaonline.org/research/volume124/number3/kumar-2015-ijca-904111.pdf
How to Execute?
Make sure you have checked the add to path tick boxes while installing python, anaconda. Refer to this link, if you are just starting and want to know how to install anaconda. If you already have anaconda and want to check on how to create anaconda environment, refer to this article set up jupyter notebook. You can skip the article if you have knowledge of installing anaconda, setting up environment and installing requirements.txt- Install the prerequisites/software’s required to execute the code from reading the above blog which is provided in the link above.
- Press windows key and type in anaconda prompt a terminal opens up.
- Before executing the code, we need to create a specific environment which allows us to install the required libraries necessary for our project.
- Type conda create -name “env_name”, e.g.: conda create -name project_1
- Type conda activate “env_name, e.g.: conda activate project_1
- Go to the directory where your requirement.txt file is present.
- cd <>. E.g., If my file is in d drive, then
- d:
 7.cd d:License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
7.cd d:License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
 8. If your project is in c drive, you can ignore step 5 and go with step 6
9. g., cd C:UsersHiLicense-Plate-Recognition-main
10. CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
11. Run pip install -r requirements.txt or conda install requirements.txt (Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
8. If your project is in c drive, you can ignore step 5 and go with step 6
9. g., cd C:UsersHiLicense-Plate-Recognition-main
10. CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
11. Run pip install -r requirements.txt or conda install requirements.txt (Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
 12. To run .py file make sure you are in the anaconda terminal with the anaconda path being set as your executable file/folder is being saved. Then type python main.pyin the terminal, before running open the main.py and make sure to change the path of the dataset.
13. If you would like to run .ipynb file, Please follow the link to setup and open jupyter notebook, You will be redirected to the local server there you can select which ever .ipynb file you’d like to run and click on it and execute each cell one by one by pressing shift+enter.
Please follow the above links on how to install and set up anaconda environment to execute files.
Please follow the above sequence if you would like to execute and the files require good system requirements to run.
Make sure to change the path of the dataset in the code
12. To run .py file make sure you are in the anaconda terminal with the anaconda path being set as your executable file/folder is being saved. Then type python main.pyin the terminal, before running open the main.py and make sure to change the path of the dataset.
13. If you would like to run .ipynb file, Please follow the link to setup and open jupyter notebook, You will be redirected to the local server there you can select which ever .ipynb file you’d like to run and click on it and execute each cell one by one by pressing shift+enter.
Please follow the above links on how to install and set up anaconda environment to execute files.
Please follow the above sequence if you would like to execute and the files require good system requirements to run.
Make sure to change the path of the dataset in the code
Data Description
The dataset was downloaded from a kaggle data repository. The dataset has been pre-processed and cleaned to remove any bias while training. Basically, it has 4800 rows and 20 columns in the dataset. The dataset contains all the information about the movie and the details of the crew members who were involved in making these movies. The columns represent the details about the movie such as title , crew, movie_id and the casting members. The rows briefly explain about those details in it. Ex: Movie Name: Avatar, The character was of Jake Sully with no gender in it and it got a popularity of more than 150.4376

Final Results
- Movie Recommendation system:
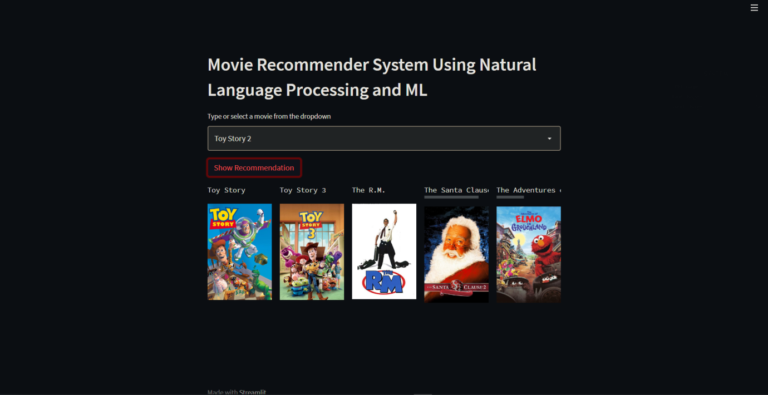
Issues you may face while executing the code
- We might face an issue while installing specific libraries, in this case, you might need to install the libraires manually. Example: pip install “module_name/library” i.e., pip install pandas
- Make sure you have the latest or specific version of python, since sometimes it might cause version mismatch.
- Adding path to environment variables in order to run python files and anaconda environment in code editor, specifically in any code editor.
- Make sure to change the paths in the code accordingly where your dataset/model is saved.






Need the source code or help?
Contact us for model weights, datasets, or guidance on running this project.