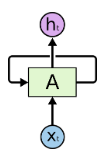
If you want to predict the next word for the sentence “I like numbers, my favorite subject is …” your answer would be “mathematics”. How do you come to that conclusion, it is because of the word “numbers”. Recurrent Neural Networks help us achieve this. They are neural networks with loops, allowing the information to stay for some time.
Xt is the input, the Network analyzes and throws out output ht. RNNs have performed decently but the problem comes when the sentence is too long and has immense data. E.g. predict the next word for the sentence “I like numbers, my favorite subject is mathematics. My brother likes space and technology, his favorite subject is ….” your answer would be “astronomy”. How do you come to that conclusion, it is because of the word “space and technology”.
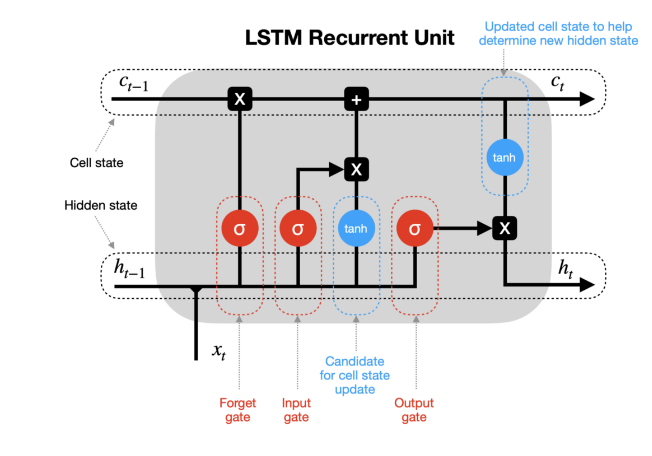
But how does the network know that word mathematics is not important now and “space and technology is important now”. Also the problem with RNNs is it cannot remember the entire sequence for long. Long Short Term Networks (LSTMs) are a special kind of RNN which are very much capable of handling long term dependencies. LSTMs has a cell state which holds the important word/information required for processing. The information in the cell state can be forgotten (removed) or added based on gates. It has 3 gates to help it decide:
Forget gate: To forget the information in the cell state. Done with the help of a sigmoid function which returns a value between 0 and 1. If 1 or closer to 1, remove the word else retain the word.
Input gate: What input should be given to the cell state done with the help of tan-h function.
Update gate: Any information that can be added to the cell state. E.g. : When “space” was in cell state, update it with the word “technology” because word “technology” is important in decision making as well .
So, before execution we have some pre-requisites that we need to download or install i.e., anaconda environment, python and a code editor.
Anaconda: Anaconda is like a package of libraries and offers a great deal of information which allows a data engineer to create multiple environments and install required libraries easy and neat.
If you already have anaconda and want to check on how to create anaconda environment, refer to this article set up jupyter notebook. You can skip the article if you have knowledge of installing anaconda, setting up environment and installing requirements.txt
1. Install necessary libraries from requirements.txt file provided.
2. Go to the directory where your requirement.txt file is present.
CD<>. E.g,If my file is in d drive, then
CD D:
CD D:\License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
If your project is in c drive, you can ignore step 1 and go with step 2.
Eg. cd C:\Users\Hi\License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
3. Run command pip install -r requirements.txt or conda install requirements.txt
(Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
All the necessary files will get downloaded. To run the code, open anaconda prompt. Go to virtual environment if created or operate from the base itself and start jupyter notebook, open folder where your code is present.
Open “FakeNewsClassifierUsingLSTM,naivesbayes.ipynb” to get the results.