
Overview
Converting words to numbers using gensim word2vec (amazon cell phone and accessories dataset)
Abstract
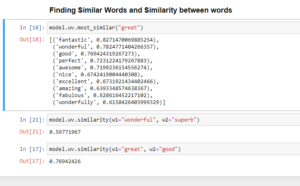
Computers do not understand words; we need to convert them to numbers to make sure computers understand them. We use the gensim library to convert words to vector form. These word embeddings on the amazon cell phone and accessories dataset will help us get similar words. After generating the word embeddings we can check similarity between words, most similar words to a given word. These embeddings are the basic building blocks for building higher level NLP projects in the future.
We used the gensim library to generate the word embeddings. Gensim is a great library to do NLP tasks. To read more about gensim and word embeddings you can refer to this article - https://radimrehurek.com/gensim/models/word2vec.html.
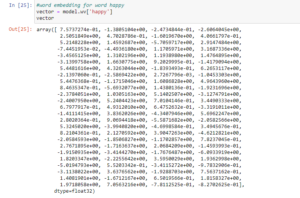
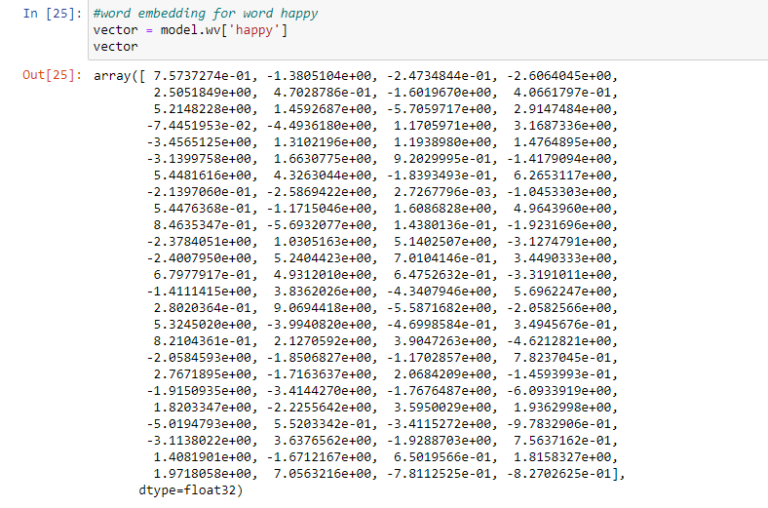
Word embeddings – Representation of word into a vector format where words with similar meanings have similar vector representation.
To give you a simple explanation of word embeddings, let us take 2 words. 1- India , 2 – China. Both are countries, have strong military, high population and hence similar in some way. So the word embeddings generated would look like India - [0,0.9,0.2,0.85,0.7] and China [0,0.8,0.3,0.80,065].
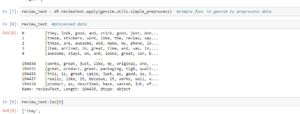
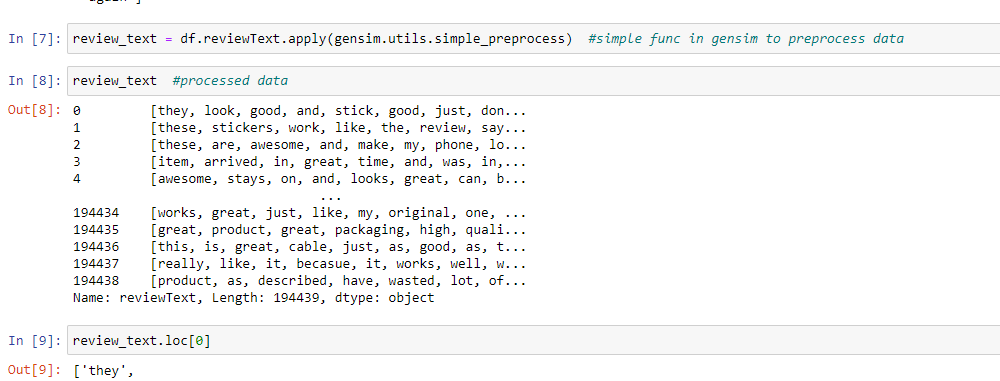
We get these word embeddings after training the model on the data and before training we preprocess the data, clean it, remove punctuations and stop words. Convert all words to lowercase and in a standardized way. After training, we get the individual word embeddings.
Code Description & Execution
How to Execute?
So, before execution we have some pre-requisites that we need to download or install i.e., anaconda environment, python and a code editor. Anaconda: Anaconda is like a package of libraries and offers a great deal of information which allows a data engineer to create multiple environments and install required libraries easy and neat. Refer to this link, if you are just starting and want to know how to install anaconda. If you already have anaconda and want to check on how to create anaconda environment, refer to this article set up jupyter notebook. You can skip the article if you have knowledge of installing anaconda, setting up environment and installing requirements.txt1. Install necessary libraries from requirements.txt file provided.
2. Go to the directory where your requirement.txt file is present.
CD<>. E.g, If my file is in d drive, then- CD D:
- CD D:License-Plate-Recognition-main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE

3. Run command pip install -r requirements.txt or conda install requirements.txt
(Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
 All the necessary files will get downloaded. To run the code, open anaconda prompt. Go to virtual environment if created or operate from the base itself and start jupyter notebook, open folder where your code is present.
All the necessary files will get downloaded. To run the code, open anaconda prompt. Go to virtual environment if created or operate from the base itself and start jupyter notebook, open folder where your code is present.

When you run the word2vec.ipynb file, you get the appropriate results.
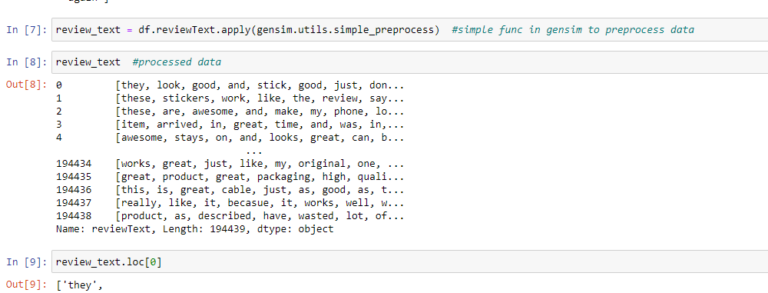

Data Description
The dataset contains reviews on amazon products. It has 9 columns like reviewerID, reviewerName, reviewText. “reviewText” column is what we will use to generate the word embeddings and contains the reviews given by users on a specific product be it good or bad. Link to the Dataset: http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Cell_Phones_and_Accessories_5.json.gz
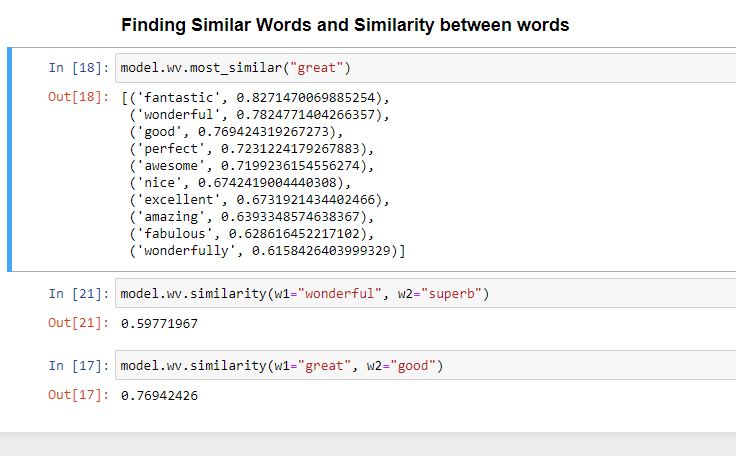
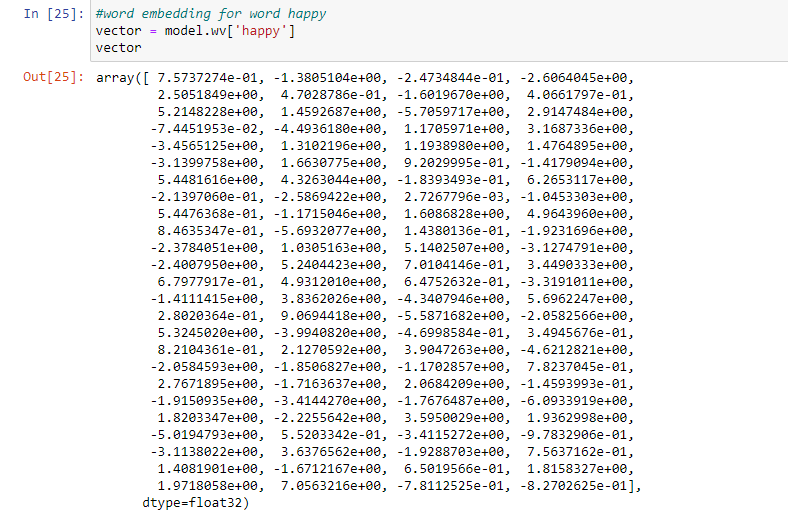
Results

Issues Faced
- Make sure to change the path in the code. Give full path of dataset/csv file you want to use.
- Make sure you have the appropriate versions of the given libraries.
Need the source code or help?
Contact us for model weights, datasets, or guidance on running this project.