Chronic Kidney Disease Prediction using M.L Algorithms
Abstract
Chronic Kidney disease is one of the major diseases which is affecting large group of population, identifying the disease in time will reduce much of complications and fatality rate can also be reduced. In this project we will be training the model on historical, which is related to kidney health and the main aim of the project is predicting weather the person will be having chronic kidney disease on not and the model will do the predictions with greater accuracy.
Code Description & Execution
Algorithm Description
Decision Tree
Decision tree is a tool for making decisions and the process for making decisions is in a tree like structure, decision tree is a supervised machine learning algorithm mostly used for predicting the outcome after computing all the attributes.
KNN
K-Nearest Neighbor is a supervised machine learning algorithm it uses feature similarity to predict the new datpoints, first the value of K is defined, which could be an integer, then the prediction is done based on how closely the new data point is to the training dataset.
How to Execute?
So, before execution we have some pre-requisites that we need to download or install i.e., anaconda environment, python and a code editor. Anaconda: Anaconda is like a package of libraries and offers a great deal of information which allows a data engineer to create multiple environments and install required libraries easy and neat.
Python: Python is a most popular interpreter programming language, which is used in almost every field. Its syntax is very similar to English language and even children and learning it nowadays, due to its readability and easy syntax and large community of users to help you whenever you face any issues.
Code editor: Code editor is like a notepad for a programming language which allows user to write, run and execute program which we have written. Along with these some code editors also allows us to debug, which usually allows users to execute the code line by line and allows them to see where and how to solve the errors. But I personally feel visual code is very good to work with any programming language and makes a great deal of attachment with user.
Note: Make sure you have added path while installing the software’s.
Install the prerequisites mentioned above.
Step1
Open anaconda prompt and create a new environment. To create an environment use the commands given below. Replace env_name by the name of environment you want to give.
conda create -n “env_name”
conda activate “env_name”
Step2
Set up jupyter notebook for your environment
conda install –c conda-forge jupyterlab
conda install –c anaconda ipython
Step3
Install necessary libraries from requirements.txt file provided.
Go to the directory where your requirement.txt file is present.
cd D:\Chronic-Kidney-Desease-Prediction-main
· Run command pip install -r requirements.txt or conda install requirements.txt
Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually. All the required files will be downloaded after you run it. I got requirement already satisfied as I already have them installed.
Step4
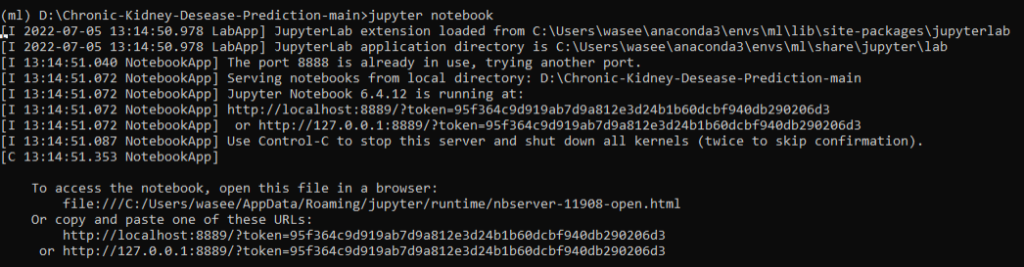
To run the code, start jupyter notebook by typing “jupytrr notebook” in command prompt, this will navigate directly to jupyter notebook in your default web browser
Open the folder containing the code, here it is chronic kidney disease prediction. When you run the Kidney_Disease_Prediction.ipynb file, you get the appropriate results.
Data Description
In the given dataset there are total of 25 columns of which first 24 are the features or the independent variables and the last column(class) is the target or the dependent variable, each attribute is a measure of some medical parameter for example:
bp is Blood Pressure
sg is Specific gravity
al is albumin
su is sugar… etc
Please go through the link to download and understand about the dataset.
Results
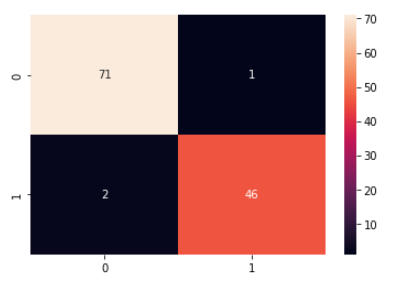
Confusion matrix for KNN classifyer
Issues Faced
While evaluating the model give proper location of the data by checking the size of test dataset as size of the data is small