Make sure you have checked the add to path tick boxes while installing python, anaconda.
Refer to this link, if you are just starting and want to know how to install anaconda.
If you already have anaconda and want to check on how to create anaconda environment, refer to this article set up jupyter notebook. You can skip the article if you have knowledge of installing anaconda, setting up environment and installing requirements.txt
- Install the prerequisites/software’s required to execute the code from reading the above blog which is provided in the link above.
- Press windows key and type in anaconda prompt a terminal opens up.
- Before executing the code, we need to create a specific environment which allows us to install the required libraries necessary for our project.
- Type conda create -name “env_name”, e.g.: conda create -name project_1
- Type conda activate “env_name, e.g.: conda activate project_1
- Go to the directory where your requirement.txt file is present.
- cd <>. E.g., If my file is in d drive, then
- d:
7.cd d:\License-Plate-Recognition–main #CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
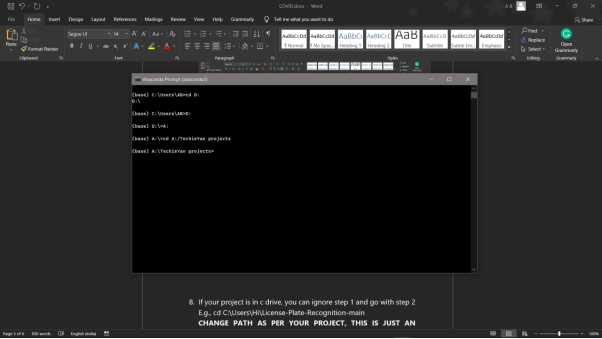
8. If your project is in c drive, you can ignore step 5 and go with step 6
9. g., cd C:\Users\Hi\License-Plate-Recognition-main
10. CHANGE PATH AS PER YOUR PROJECT, THIS IS JUST AN EXAMPLE
11. Run pip install -r requirements.txt or conda install requirements.txt (Requirements.txt is a text file consisting of all the necessary libraries required for executing this python file. If it gives any error while installing libraries, you might need to install them individually.)
12. To run .py file make sure you are in the anaconda terminal with the anaconda path being set as your executable file/folder is being saved. Then type python main.pyin the terminal, before running open the main.py and make sure to change the path of the dataset.
13. If you would like to run .ipynb file, Please follow the link to setup and open jupyter notebook, You will be redirected to the local server there you can select which ever .ipynb file you’d like to run and click on it and execute each cell one by one by pressing shift+enter.
Please follow the above links on how to install and set up anaconda environment to execute files.
Note: There are 4 different files each seeves different purpose such as,
- Preprocess.ipynb consists of all the data cleaning steps, which are necessary to build a clean and efficient model.
- main.ipynb consist of major steps and exploratory data analysis which allow us to understand more about the data and behavior of it.
- Variable_Selction.ipynb consists of data reduction/dimensionality reduction techniques such as Sequential feature selector method to reduce the dimensions in the data and compare the model scores before and after dimensionality reduction.
- Combined_main_var.ipynb consists of combination of main.ipynb and variable_selection.ipynb to make it more clear and understable for the audience.
Please follow the above sequence if you would like to execute and the files require good system requirements to run.
Make sure to change the path of the dataset in the code