

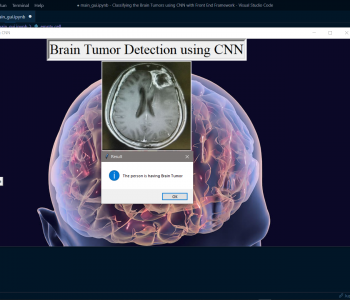
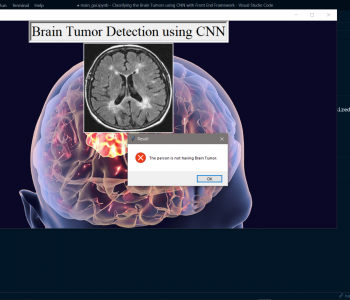
Evaluation metrics are considered one of the most important steps in any machine learning and deep learning project, where it will allow us to evaluate how good our model is performing on the new data or on unseen data. There are a lot of evaluation metrics such as confusion matrix, roc_auc curve, f1_score, recall, and precision, and each of which works for the specific problem we deal with. So, for our project, we have gone with confusion matrix the OG of every evaluation matric were using it, we have calculated the accuracy and another metric, which has given a conclusion that the model is performing very well on new data.
